



谷歌又双叒叕被开了一张巨额罚单。
前不久,欧盟委员会甩给了谷歌一张价值24亿欧元的天价罚单,刷新了“史上最高额罚单”的记录,原因是其“滥用市场上的主导地位,在搜索结果中偏向自家的服务”。

妈呀这是多少钱啊好吓人 | duitang.com
不过,谷歌可能很快刷新个人最高记录!
自打5月25日欧盟 “通用数据保护法” (General Data Protection Regulation,下文简称GDPR)生效后,奥地利律师、隐私保护倡导者马克思·史莱姆(Max Schrems)已经开始起草上诉文件,拎着一张罚单再一次瞄准了谷歌。这一次,罚单上估算的金额是——37亿欧元!
然而,谷歌可能并不会成为 “最高额罚单连续记录保持者” ,因为史莱姆根据GDPR也同时起诉了Facebook,他认为后者应被罚的数额是39亿欧元……

呼吸一下金钱燃烧的气息 | 《蝙蝠侠:黑暗骑士》
这个能让科技巨头们都闻风丧胆的GDPR,号称“史上最强数据保护法”!
GDPR究竟怎么个强法?
首先,它对所保护的用户数据定义非常严格,覆盖范围很广。我们来看一下GDPR保护的个人数据都包括些什么:

基本上,是关于我们的一切信息了!
其次,它对企业的要求非常高。比如我们看看如下几条:
1. 用户许可:协议必须说人话!
任何企业只要收集用户数据,就必须要得到用户的许可。而且,GDPR还对用户协议的行文给出了规范,比如说,用户协议必须写得清晰易读,不能写又长又难懂的文字,不能全篇都是难懂的法律术语。
嗯,苹果的程序员们在2014年IOS用户协议里的脑洞“苹果总部5层的托尼身上有一股沙丁鱼的味道”,如果他们真的写了,不知道放在今天会不会被罚款......(苹果程序员:啊喂,我们的表达没有任何歧义呀?好吧,虽然这个其实也是我们YY的把你骗了。)
图 | HuffPost UK
不过GDPR这个规定也是对用户很友善了,说人话的用户协议,想想也是令人感动呢。
相信很多人跟我一样看都不看就点了“同意”。
2. 数据遗忘权:用户可以反悔
用户可以“出尔反尔”!也就是说,我过去因为懒得看协议随手授权给你使用的个人信息,现在我可以反悔,而公司必须删除干净,而且要阻止之前授权的第三方继续使用用户要求删除的信息。

3. 数据保护官:操心劳力的背锅侠
GDPR要求企业有专员负责用户数据保护,而且必须设计专门的数据保护构架。对于数据保护官(Data Protection Officer,DPO)的指责和雇佣细节也给了超级多的要求。
听上去是一个非常不得了的岗位,不知道一旦企业被罚DPO是不是就要出来背锅……
4. 泄露通知:有锅,企业必须马上背!
一旦发生数据泄露,公司必须在72小时内通知用户。
义无反顾背起所有飞来的锅,不知多少公司的DPO会哭晕在厕所。但是作为用户,感觉还是满意的。

图 | 故宫博物院
5. 领域扩展:不在欧洲?也能被罚
这一条特别厉害。意思是说,不管你的公司在哪里,只要你的用户中有欧盟公民,你就得乖乖按照我们的来。
神州大地上热火朝天创业的小伙伴们这里要敲黑板注意啦:别自欺欺人,觉得反正我不在欧洲,他们罚不到我,也别管你的竞争对手干了啥没干啥,只要你的产品有欧洲用户,赶紧吧,麻溜利索地准备合规;万一中奖被罚了,这些年熬的夜全都付诸东流了……

关于GDPR最最最最重要的是:罚款超!级!高!
一旦发现违规,欧盟委员会将对贵公司处以罚款,可能是2000万欧元,也可能是该企业全球营业额的4%,哪个更高就按照哪个罚!

欧盟:来啊,违规啊,违规就要罚钱呀!
总结一下GDPR是怎么成为“史上最强”的:1. 对保护数据定义超级广; 2. 对企业要求特别狠;3. 罚款额度变态高。
欧盟为什么要这么严格?
首先,公民的隐私权需要被维护。
这一点无需太多解释,想一下平时莫名其妙接到的“你好,廊坊的房子了解一下?”“你好,需要资金周转吗?”“彩票了解一下”这类电话,如果这些骚扰都被严惩约束,世界该是多么可爱!
因为这些骚扰一来很烦人,二来让人觉得自己被监视有种毛骨悚然感,三来,总是提醒我们自己是多么的穷……
还有一点很重要,就是商业公司擅自使用用户数据带来的潜在危害。
还记得3月份重创Facebook的剑桥分析事件吗?如果说个人数据被用来训练推荐算法、定向广告投放之类的情景,还属于吃瓜群众能够理解的范畴的话,利用用户信息数据有针对性地引导选民便是无法被容忍的了。

图 | Pixabay
实际上,欧盟也不是仅仅因为选举才临时起意出台这么一个法规的。
GDPR的前身是1995年的《数据保护指令》(Data Protection Directive)95/46/EC 。2012年初,欧盟委员会正式开始修改更新数据保护条例,经过四年努力,于2015年底完成条例法案,并于2016年4月被欧盟理事会和欧洲议会采纳。
两年过去,大家准(zuō)备(sǐ)得怎样?
处理数据隐私无疑是一项大工程。普华永道在2017年初曾发布一项关于GDPR合规的调查结果,其中,68%被调查的公司表示,为了合规公司不得不投资100美元~100万美元;而另有9%的公司预估在合规上将投入超过1000万美元。换算成人民币,堆成一百元钞票,体量大约是介于下图两者之间的高度吧……
图 | 果壳
所以,2015年底通过法案后,欧盟也没有急吼吼地立即开始执行,而是给了各家公司两年的时间做过渡准备,GDPR被定于2018年5月25日开始正式生效。那么,大家作业完成情况如何呢?

我们搜罗了一下各大公司的反应,发现大家通常采取的行动有如下几类:
1. 吐槽但还是乖乖行动型
英特尔的高管大卫·霍夫曼(David Hoffman)曾吐槽“如此严厉的惩罚会打击商业和投资”。不过,看上去英特尔还是回去仔细研究了法规,并且做了详细的分析报告。

图 | 英特尔
2. 法规生效前疯狂抱佛脚型
两年过去了,大部分企业发现自己好像还是什么都没做,那就让用户“允许”我们使用数据吧!于是,就有了5月份至今我们收到的海一样多的邮件和提示信息,然后和往常一样,你看也没看就点了一堆“接受”……
图 | Minh Uong / The New York Times
这其中有漏网之鱼,企图让你没注意就点击“接受”;其中也有强势流氓行为——如果你不属于那些看也不看就狂点“接受”的人群,也许你已经注意到了有些公司比较流氓,因为,“拒绝”的选项根本点不了!
也就是说,有些公司的“隐私条例”其实有点霸王条款之嫌——同意我们收集信息,或者你别用我们的产品呀!
我曾对一款软件坚持卸载了一个星期,最后因为社交需求还是很没面子地安装回来并且点了“接受”,内心羊驼万千……
3. 直接放弃欧洲用户市场型
也有些公司画风比较清奇,为了不“耍流氓”,他们面对即将生效的GDPR采取了最简单粗暴的做法——直接拒绝欧洲用户登陆!也许是比较了做好万全数据保护架构的成本、选择“不选择使用”用户隐私信息折损的收入、巨额罚款这几个看起来都不太开心的选项后,最终痛定思痛舍弃了欧洲这块市场吧。

这是我们最后一个月服务欧盟用户了!| unroll.me
4. 关门大吉型
所有的被GDPR影响的企业中,有一家叫做Klout的公司的动作看上去最疯狂——它直接关!停!了!
Klout是一个计算个人在网络上影响力的平台,它会根据一个人在社交平台上的粉丝数等一系列信息,来给出一个0~100的“影响力指数”。
Klout在2012年左右风头最盛,当时还引起了关于“世界上最有影响力的个人究竟是奥巴马还是贾斯汀·比伯”的大讨论(不过后来它因为修改算法让奥巴马排在比伯前面而受到了群嘲)。
图 | Forbes
Klout在2014年被一家叫做Lithium Technologies的社交媒体营销公司收购,近几年逐渐销声匿迹,直到近期的“关停通知”才让它回光返照了一下。Lithium的CEO在给客户的邮件中写到,“收购Klout为Lithium的人工智能和机器学习的发展提供了宝贵的价值,但是它作为一项独立的业务,已经不再是Lithium长期发展的一部分了。”
Lithium公司的这个行为也许可以这样解读:收购Klout为母公司带来了大量的用于进行人工智能和机器学习的用户数据,为了保留这部分数据的使用权,母公司砍掉了这个反正已经没人记得的子公司;如果法律追究起来,数据的“收集”是由Klout完成的,而这家公司已经死掉了,你罚不到我。
5. 装死型
不过,比起这些这部分绞尽脑汁花样百出的公司,还有相当大一部分公司选择了装死。一家叫做The Ponemon Institute 的机构在4月份做了一项涉及1000家企业的调查,其中60%的科技公司表示“在期限来临时根本没法做好100%的合规”—— 反正那么多人呢,先看看别人怎么办吧……

我不听我不听,太难了,同桌小明也没交作业!
关于GDPR的一些争议
作为普通用户,自己的数据隐私得到保护,无疑是一件好事。
在此之前,作为用户,我们被互联网时代培养了很多习惯:导航解救了路痴,外卖软件可能会推荐你更可能喜欢的参餐馆而避免踩雷,购物软件可以根据我们的购物习惯告诉我们常用的商品什么时候打折……

但是,互联网时代有一个让人可能不太舒服的事实——“如果你没有付费,那说明你就是商品”。
互联网时代带给了我们无数便利,更多的时候,这些便利是我们作为用户被选择的结果——用户根本没有选择的余地,就作为样本被收进了数据库,成为无数商业公司分析的对象。
当商业巨头说出“中国人愿意用隐私换取便利”的言论时,当某手机的升降机械摄像头成了“流氓软件鉴定器”时,掀起的民愤也表明了中国用户对用户隐私的关注正在逐步崛起。
不过,法规严格到GDPR这种程度,也有一些学者表示了担忧。
比如人工智能领域的专家、华盛顿大学计算机系的教授彼得罗·多明格斯(Pedro Domingos)在今年1月28日曾连发两条推文,一条说“5月25日起,欧盟将要求算法解释它们的结果,深度学习变成违法”,另一条则讽刺“欧盟说,数据只能发挥它‘最初设定的作用’,拜拜青霉素,拜拜X光”(青霉素与X光的发现都源于意外,并非出于“最初设定的作用”)。
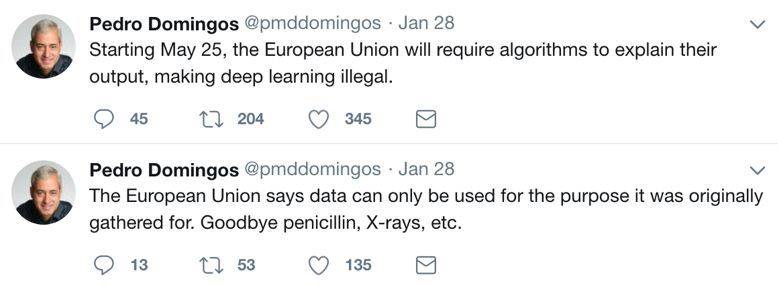
图 | Twitter
多明格斯教授的担心不无道理:一方面,过于苛刻地对待数据处理的确会扼杀很多计划之外的发现,影响技术的创新;同时,机器学习的发展本身依赖于大量的数据,而各大商业公司收集的用户数据,对于研究而言都是宝贵的材料,缺乏海量的、全面的关于人的数据可以预见地会影响技术的发展。
不过,这里引出的科技研究、商业公司的利益、用户隐私安全之间如何平衡,也是相当复杂而且处于动态发展中的难题。

陆奇 | Dcoetzee / Wikimedia Commons
上周大家被刷屏的“Y Combinator中国01号员工”陆奇先生在媒体采访中提到了一个理想中的“数据生态”:“我希望以后会有一个数据生态,让与人有关的数据最终属于个人,他有权利决定在什么情况下、出于什么目的,让某个企业使用他的数据。在这个生态里,创业公司也可以得到用户的支持,例如用户对教育有热忱并且希望支持教育公司创业,他就可以将自己的数据开放给这家公司使用。”
实现这个理想的“数据生态”是一个道阻且长的过程,也许来势汹汹的GDPR是一个先行的实践,最终的平衡很可能要在很多的争论和矛盾中才能逐渐达到吧!
